

Searching for a Twitter follower scraper usually points to a very specific need:
You want structured access to follower data from an X (Twitter) account.
This intent cuts across roles and industries. Marketers want to understand who actually makes up an audience. Researchers look for behavioral patterns and network effects. Growth strategists analyze follower quality and overlap. Brand managers study competitor communities to uncover positioning gaps and partnership opportunities.

Follower data is valuable because it answers questions that surface-level metrics cannot:
- Who is paying attention?
- Who has influence within this audience?
- How credible or active are these followers?
- Where do communities overlap or diverge?
That’s why follower scraping tools are so widely searched.
However, there’s a gap between what people expect these tools to do and what most of them actually deliver.
The uncomfortable truth is that many Twitter follower scrapers:
- rely on fragile scraping methods
- return outdated or partial datasets
- silently miss large portions of followers
- operate outside platform rules
- expose users to account or IP risk
In other words, the data often looks complete, but isn’t.
This guide exists to clear up that confusion.
You’ll learn:
- what a Twitter follower scraper really does behind the scenes
- why most scraping-based tools struggle or fail in 2026
- the critical difference between scraping, exporting, and downloading follower data
- and how to safely access accurate, up-to-date follower lists using an official, API-based approach with tools like Circleboom
Because when follower data drives decisions, accuracy and safety matter more than speed or shortcuts.

What Is a Twitter Follower Scraper?
A Twitter follower scraper is a tool designed to collect structured data about the followers of an X (Twitter) account. Instead of manually scrolling through thousands—or millions—of profiles, these tools extract follower information in bulk and organize it into usable datasets.
Depending on the tool and method used, a follower scraper may collect data such as:
- usernames and @handles
- follower and following counts
- profile bios and descriptions
- verification status (blue, organization, legacy)
- profile URLs and avatars
- language and location (when available)
- activity indicators, such as recent posting behavior
For marketers, analysts, and researchers, this data becomes the foundation for audience analysis, competitor research, influencer discovery, and campaign targeting.
How “Scraping” Originally Worked
Historically, the term scraping referred to a very specific technical process:
- crawling publicly accessible Twitter profile pages
- parsing HTML content from the web interface
- extracting visible follower data without authentication
- bypassing or avoiding official APIs altogether
This approach worked years ago because:
- Twitter’s frontend exposed more data publicly
- rate limits were looser or nonexistent
- anti-bot protections were less sophisticated
As a result, many early follower scrapers were built quickly, cheaply, and without regard for long-term stability.
Why That Approach No Longer Works in 2026
X’s platform has changed fundamentally.
Today:
- follower lists are dynamically loaded
- HTML structures change frequently
- aggressive bot detection monitors scraping behavior
- IPs and accounts interacting with scraped data are flagged
- large portions of follower data are hidden behind authenticated API access
As a result, traditional scraping methods now produce:
- incomplete follower lists
- missing or outdated metadata
- inconsistent results between runs
- increased risk of blocks or bans
In short, what used to be called “scraping” is no longer a reliable or safe way to collect Twitter follower data.
That’s why modern tools have shifted away from raw scraping and toward API-based exporting, a critical distinction we’ll break down next.
Why Most Twitter Follower Scrapers Are Broken (or Dangerous)
At a glance, many Twitter follower scrapers look functional. They promise fast results, CSV downloads, and “unlimited” exports. But under the surface, most of these tools are either technically broken or actively risky to use in 2026.
Let’s start with the biggest issue.
1. Web Scraping No Longer Reflects Real Data
X (Twitter) no longer exposes follower data in a static, scrape-friendly format.
Follower lists today are:
- dynamically loaded via JavaScript
- protected by aggressive rate limits
- segmented and throttled based on account size
- partially hidden behind authenticated requests
This means that what you see in a browser is not what a scraper actually receives.
What This Breaks in Practice
Traditional scrapers rely on:
- HTML page crawling
- visible DOM elements
- repeated unauthenticated requests
But modern X pages:
- load followers in batches
- change request parameters frequently
- block repeated fetches
- return empty or partial responses after thresholds are reached
As a result, scrapers often:
- stop after the first few thousand followers
- skip entire segments of the follower list
- fail silently when throttled
- mix cached data with live data
The Result: Incomplete and Misleading Datasets
Most web-based follower scrapers now return:
- missing followers
- outdated follower counts
- incomplete profile metadata
- inconsistent results between runs
In real-world testing, many tools quietly return 30–60% incomplete follower lists, without any warning or error message.
You don’t get an alert that data is missing.
You just get a file that looks complete.
That’s the real danger.
If you’re using this data for:
- audience analysis
- influencer identification
- ad targeting
- academic research
- competitor intelligence
Then incomplete data doesn’t just reduce accuracy, it actively leads you to the wrong conclusions.
And because the tool doesn’t tell you what’s missing, you don’t know you’re working with a distorted view of reality.
This is why “scraping” follower data the old way is no longer just outdated, it’s unreliable by design.
Keep in mind that the API provides a more accurate real-time data stream than the X interface itself. While the platform UI may experience lag, the API captures and reflects new developments instantaneously.
Circleboom has the official Enterprise API, we don't scrape data from X!
2. Unofficial Scrapers Violate Platform Rules
Most so-called “free” Twitter follower scrapers cut corners to function at all. Instead of using approved data access methods, they rely on fragile workarounds such as:
- scraping logged-out or semi-public pages
- hijacking shared browser sessions
- calling undocumented or unofficial endpoints
- rotating IPs to avoid detection
These approaches may appear to work temporarily, but they are fundamentally unstable.
Why This Is a Problem in 2026
X has dramatically increased enforcement around data access. Its systems now actively monitor:
- abnormal request patterns
- repeated unauthenticated access
- session reuse across IPs
- scraping-like behavior at scale
As a result, unofficial scrapers tend to:
- break without warning when page structures change
- return empty or partial datasets
- trigger IP bans or captchas mid-export
- flag accounts indirectly through suspicious activity
In many cases, users don’t realize the risk because the scraping happens “outside” their account. But the data requests are still traceable, and the consequences can include:
- blocked access to follower lists
- degraded reliability across future exports
- account trust signals being quietly reduced
In short, these tools operate in constant conflict with the platform. They are not designed to be stable, only to work until they don’t.
3. Large Accounts Are Impossible to Scrape Reliably
Even if unofficial scraping were allowed (it isn’t), it simply doesn’t scale.
Once an account crosses certain thresholds such as:
- 50,000+ followers
- rapid follower growth
- international, time-zone-distributed audiences
browser-based scraping begins to collapse.
What Happens at Scale
For large or fast-growing accounts, scraping becomes:
- painfully slow, sometimes taking hours or days
- inconsistent between attempts
- prone to timeouts and missing batches
- unable to keep up with real-time changes
Follower lists are served in segmented chunks, throttled aggressively, and reshuffled frequently. Scrapers often:
- duplicate entries
- skip newer followers
- miss inactive or protected segments
- fail entirely after reaching internal limits
This makes scraping unsuitable for any use case where accuracy matters.
That’s why modern, professional tools stopped calling this process “scraping” altogether.
Instead, they focus on official exporting; using authenticated, rate-aware APIs that return complete, up-to-date datasets without violating platform rules.
Because in 2026, the real question isn’t:
“Can I scrape followers?”
It’s:
“Can I access follower data safely, completely, and reliably?”
And scraping, as a method, no longer meets that bar.
Why Circleboom Is Different from Typical Twitter Follower Scrapers
Circleboom is an official X Enterprise developer, which changes everything.
That means:
- access to approved APIs
- real-time follower data
- strict rate-limit compliance
- zero scraping hacks
- no browser automation
Instead of “scraping,” Circleboom exports followers safely and completely.
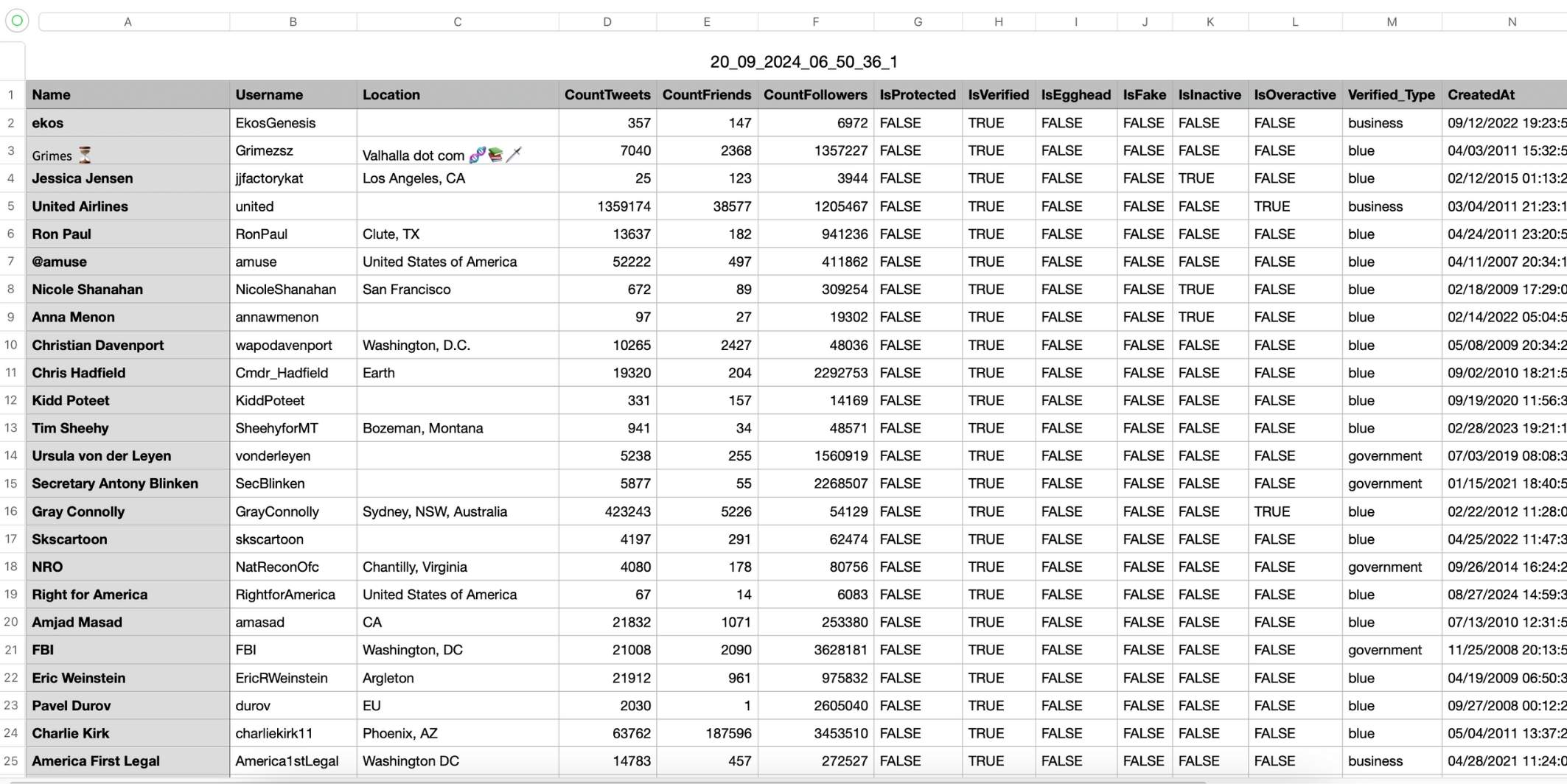
What You Can Do with Circleboom’s Twitter Follower Export Tool
Using Circleboom, you can:
- export followers of any public X account
- download them as CSV or Excel
- get up-to-date follower lists
- filter followers by quality signals
- analyze large accounts without data loss
This is exactly what people think a follower scraper does, but done correctly.
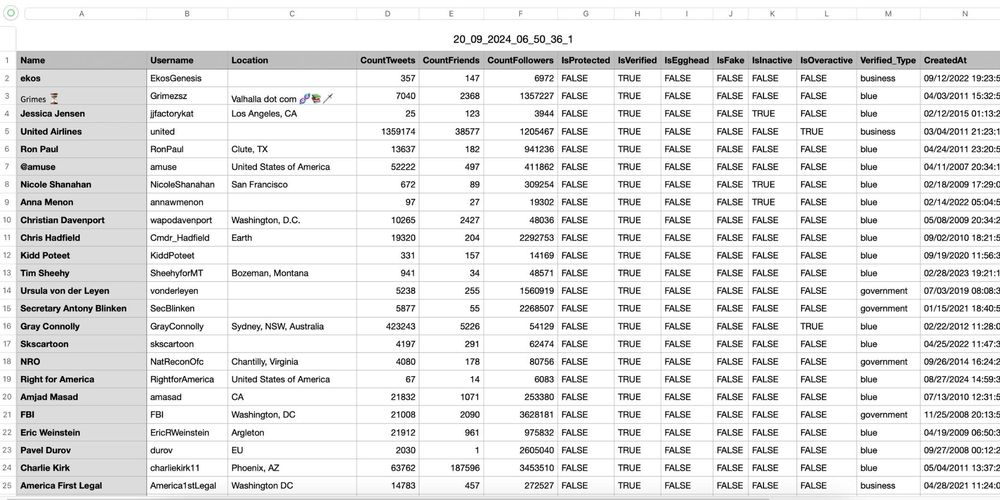
Circleboom also allows you to scrape all tweets of a person on X.

Step-by-Step: How to Scrape (Export) Twitter Followers Safely
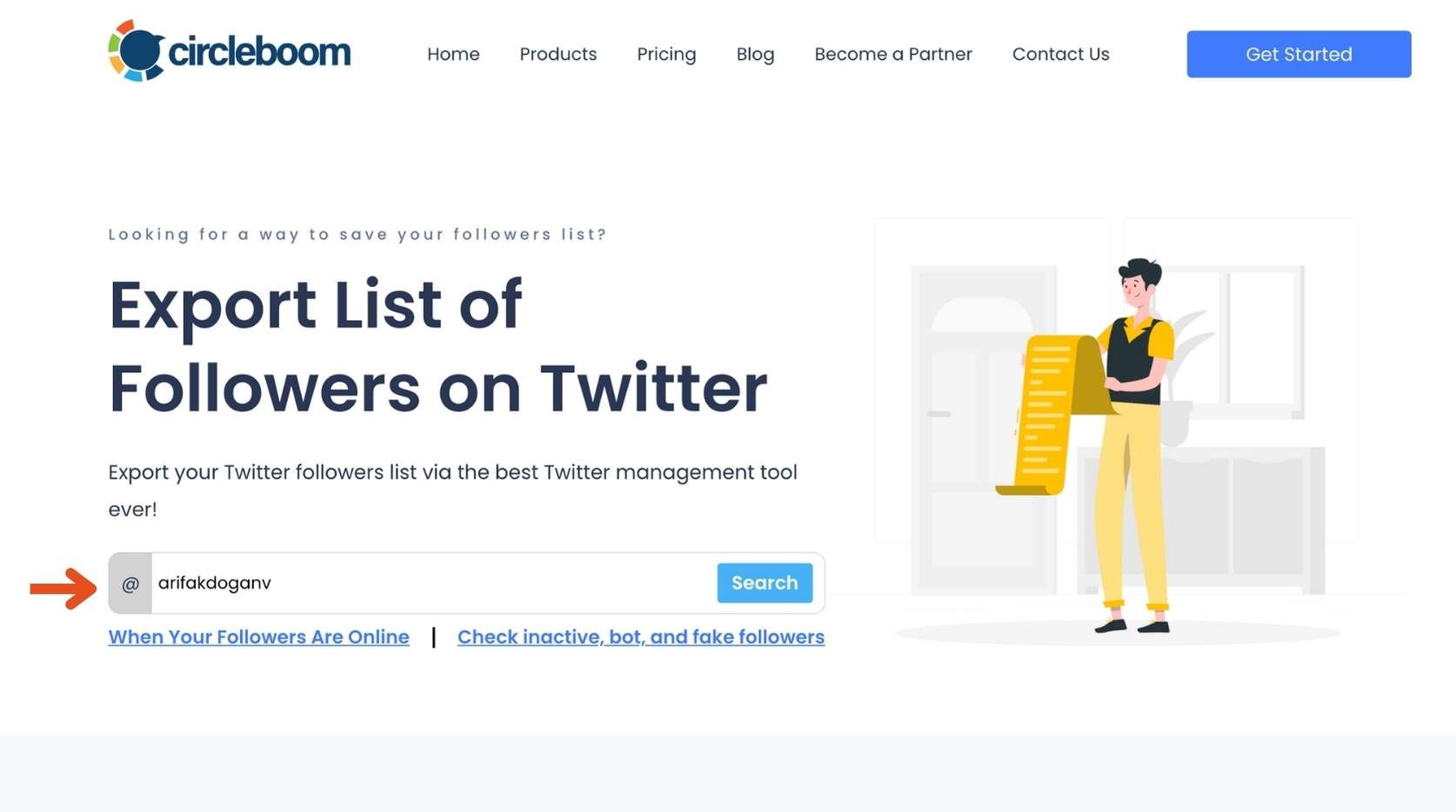
Step #1: Go to the Circleboom Export Twitter Followers List Window: First, navigate to the Circleboom "Export Twitter Followers List" window.
Here, you’ll need to enter the Twitter username of the account whose follower list you want to export. This can be your own account or any other Twitter user’s account. After entering the username, click the 'Search' button.
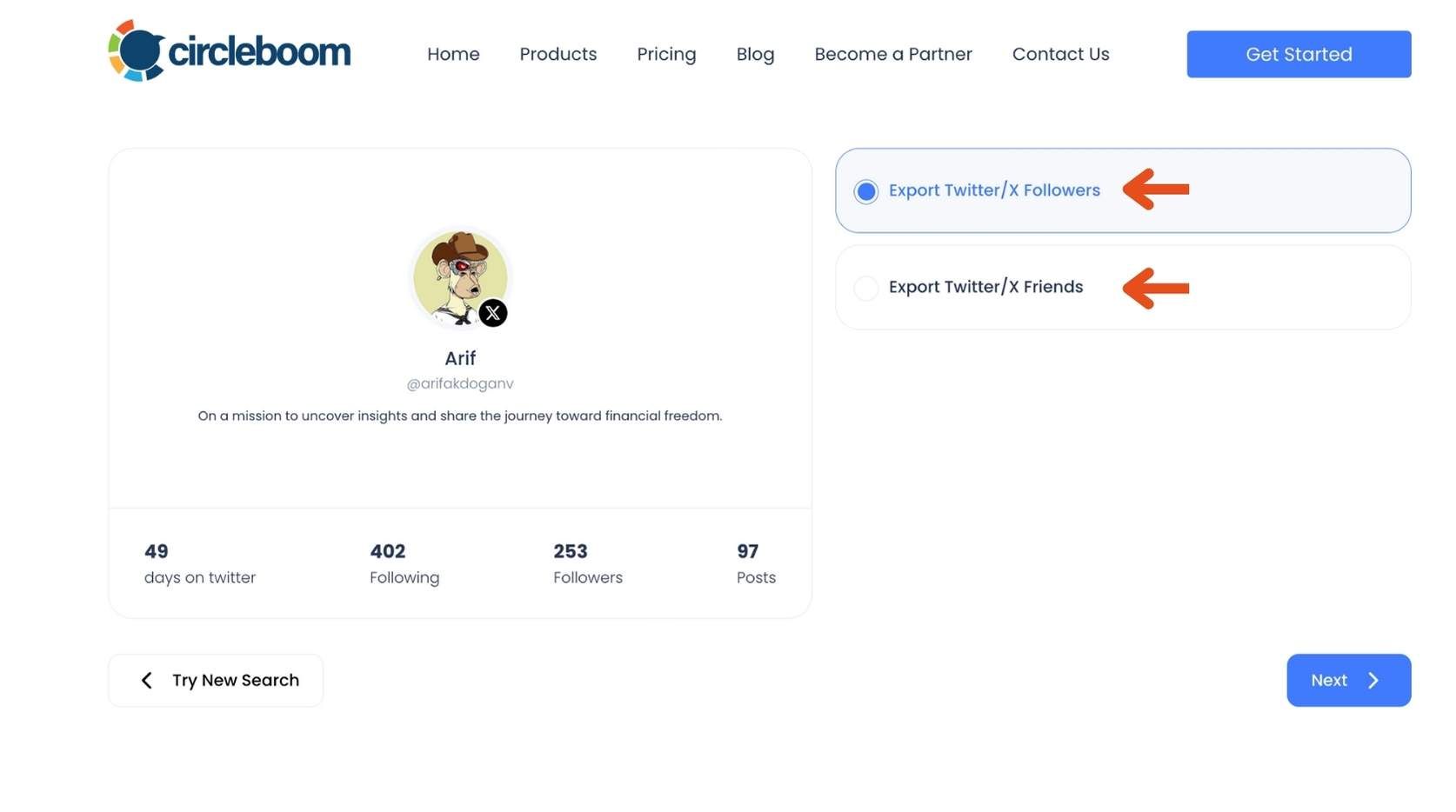
Step #2: Choose the List You Want to Export: Circleboom offers two options: you can export either the followers or the following list of the account you searched for.
In this case, since we only want to export the follower list, select "Export Twitter/X Followers" and click 'Next'.
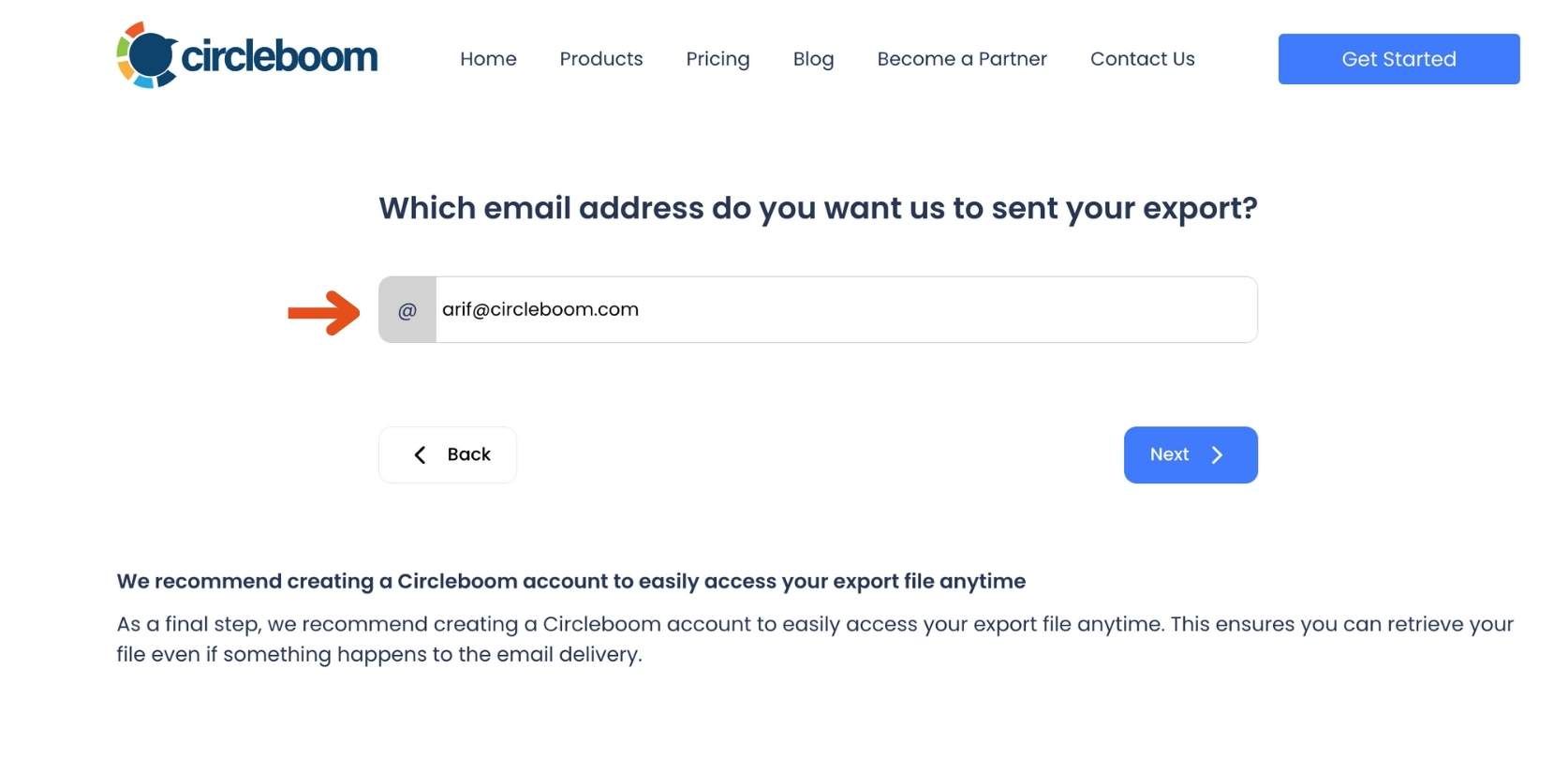
Step #3: Provide Your Email to Receive the CSV File: Circleboom will send the exported follower list to your email in a CSV format.
Enter your email address in the provided field and click 'Next'.
Step #4: Receive the Follower List via Email: Congratulations! Circleboom will send you the follower list of the account you searched for in just a few minutes.
You’ll now have access to all the details of the account’s followers in a downloadable CSV file.
Why Marketers Prefer Exporting Over Scraping
Better Targeting
Exported follower lists can be used to:
- identify influencers
- build outreach lists
- create ad audiences
- study niche communities
Scraped data often breaks during analysis.
Cleaner Analytics
API-based exports:
- eliminate duplicates
- normalize metadata
- preserve structure
That’s essential for Excel, CRM, or BI tools.
Zero Account Risk
Scraping tools can:
- trigger IP bans
- expose accounts
- violate terms
Circleboom’s exports are rate-aware and compliant.
Use Cases: Who Needs a Twitter Follower Scraper?
Brands & Agencies
- competitor audience analysis
- influencer discovery
- campaign targeting
Researchers & Analysts
- network analysis
- community mapping
- trend detection
Creators & Founders
- validate follower quality
- spot brand advocates
- identify power followers
In all cases, exporting beats scraping.
FAQs: Twitter Follower Scraping & Exporting
Is it legal to scrape Twitter followers?
Scraping via unofficial methods can violate platform rules. Exporting public data through approved tools is safer and compliant.
Can I scrape followers without logging in?
Most tools claiming this deliver incomplete data. API-based exports require authentication for accuracy.
Can I scrape followers of any account?
You can export followers of public accounts. Private accounts are protected by design.
Is Circleboom safe to use?
Yes. Circleboom operates as an official X Enterprise customer and respects all rate limits.
What format can I download followers in?
CSV and Excel, ready for analysis or upload into other tools.
Final Verdict: Stop Scraping. Start Exporting.
If you’re searching for a Twitter follower scraper, what you really want is:
- full data
- updated data
- zero risk
- scalable results
Scraping promises speed but delivers instability.
Circleboom replaces scraping with exporting, and exporting with confidence.
{kind=link}
